
「開発段階では精度98%だったのに、本番に出したら全然使えない——」
AI開発プロジェクトを進めている担当者から、こうした声をよく聞きます。データ分析や機械学習を活用したシステムを外注していると、開発者から「テストでの精度は問題ありません」という報告を受けながら、いざ本番稼働してみると期待した結果が出ないことがあります。
この問題の原因として頻繁に挙げられるのが「過学習(オーバーフィッティング)」です。過学習は機械学習の世界では古くから知られる課題ですが、発注する側・管理する側の担当者にとっては、なかなかイメージしにくい概念でもあります。
本記事では、過学習とは何か、なぜ問題になるのかを分かりやすく解説します。さらに、AIシステムを外注・管理する立場の担当者が「発注先に確認すべきポイント」まで踏み込んでお伝えします。コードや数式は一切使わず、具体的な事例を通じて理解できる内容になっています。
はじめての AI 導入ガイド――中小企業が失敗しないための7ステップ

この資料でわかること
AI導入を検討しているが「何から始めればよいか分からない」中小企業の意思決定者に対し、導入プロジェクトの全体像を一気通貫で提示し、「自社でも着手できる」という確信と具体的な行動計画を持ってもらうこと。
こんな方におすすめです
- AI導入を検討しているが、何から始めればよいか分からない
- ベンダーの選び方や費用感がつかめず、判断できない
- 社内でAI導入の稟議を通すための資料が必要
入力いただいたメールアドレスにPDFをお送りします。
過学習(オーバーフィッティング)とは
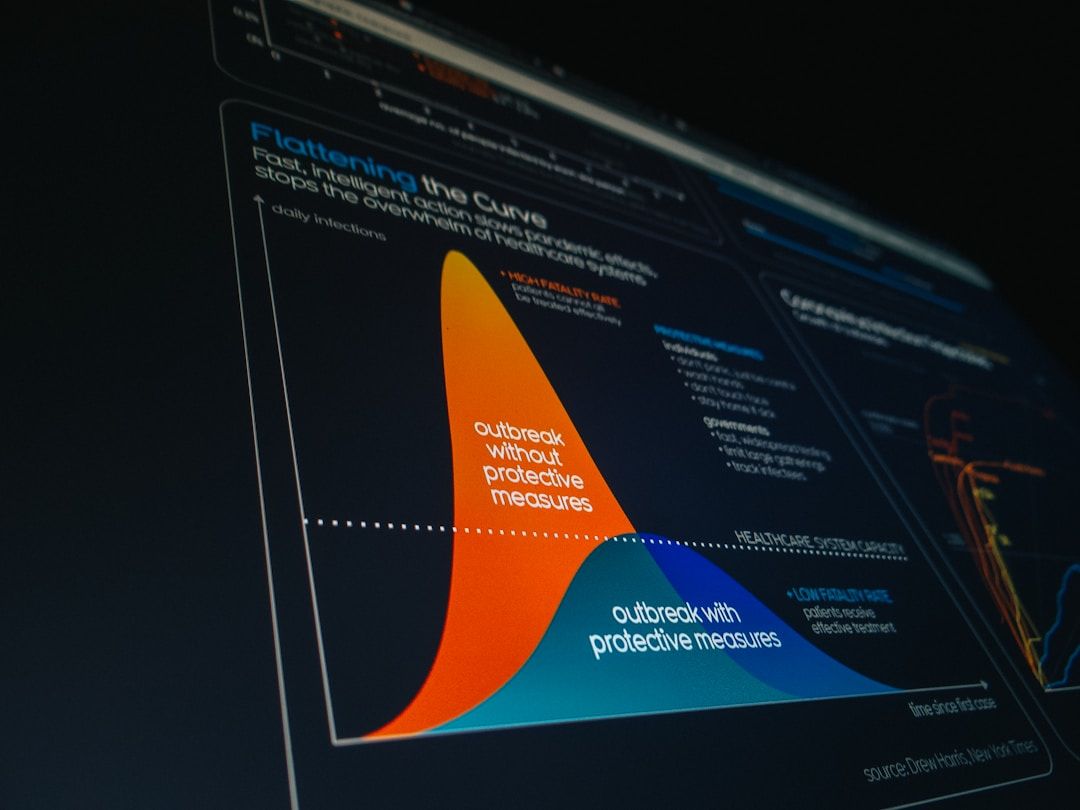
過学習(英語では「Overfitting」)とは、機械学習モデルが学習に使ったデータに過剰に適合してしまい、新しいデータに対してうまく機能しなくなる状態のことです。
もう少し分かりやすく説明しましょう。
機械学習のモデルは、大量のデータからパターンを学んで予測を行います。たとえば「過去の受注データから次月の需要を予測する」「顧客の属性から購買確率を推定する」といった用途です。このとき、モデルは「学習データ」と呼ばれる過去のデータを使って訓練されます。
問題は、学習データで訓練したモデルが、そのデータに含まれる偶然のノイズや特殊なパターンまで記憶してしまうことです。その結果、学習に使ったデータに対しては非常に高い精度を発揮する一方で、実際に使われる本番データに対しては精度が大幅に落ちてしまいます。
訓練データと未知データの違い
機械学習では、データを「訓練データ」と「テスト(検証)データ」に分けて使います。
- 訓練データ: モデルが学習(パターンを覚える)のに使うデータ
- テストデータ: 学習後のモデルが「実際に使えるか」を検証するためのデータ
健全なモデルは、訓練データもテストデータも同程度の精度を発揮します。しかし過学習が起きたモデルは、訓練データでは「99%の精度」でも、テストデータでは「60%の精度」というような大きな開きが生じます。
過学習を視覚的にイメージする
受験勉強で「特定の問題集だけを丸暗記してしまった生徒」をイメージしてみてください。
その生徒は、同じ問題集を繰り返し解けば満点近く取れます。しかし、初めて見る問題(本番の入試)が出ると途端に解けなくなります。「答えを覚えた」だけで「解き方を理解した」わけではないからです。
機械学習モデルの過学習も、これと同じ状態です。学習データの「答え」を覚えてしまったモデルは、新しいデータに対して汎用的な予測ができなくなります。
過学習はなぜ問題なのか

「精度が下がるくらいなら、学習データだけで使えばいい」と思うかもしれませんが、実際にはそれはできません。機械学習システムの目的は、過去のデータで訓練したモデルを使って未来の未知データを予測・判断することだからです。
つまり、本番で使うデータは必ず「モデルが学習していない新しいデータ」になります。
過学習状態のモデルが本番で失敗するパターン
具体的な失敗パターンを3つ見てみましょう。
事例1: ECサイトの需要予測
コロナ禍の2020〜2021年のデータだけを使って需要予測モデルを開発した場合、学習データには「巣ごもり需要」「在宅勤務に伴う購買傾向」が色濃く反映されます。モデルはそのパターンを「正解」として学習します。
社会活動が回復した2022年以降に同じモデルを使うと、外出用アイテムの需要を過小評価し、部屋着を過剰発注するような誤った予測をしてしまいます。これはモデルが特定の時期の傾向を「記憶」してしまった過学習の典型例です。
事例2: 採用スコアリングシステム
過去の採用データをもとに「合否判定AI」を開発した場合、学習データに含まれる「偶然の相関」(たとえば、ある特定の趣味欄の記述をした候補者が入社後に活躍したという偶然)まで学習してしまうことがあります。本番で使うと、本質的なスキル・経験よりも些細な特徴を重視した的外れな判定をしてしまいます。
事例3: 不正検知システム
限られた不正事例データで学習した不正検知モデルは、「見たことのある不正パターン」しか検知できなくなります。少し手口を変えた新たな不正は見逃してしまいます。
これらの失敗は、開発段階ではなかなか表面化しません。開発者が「精度が高い」と報告した時点では問題がなく、本番稼働後に初めて発覚するという点が過学習の厄介なところです。
過学習が起きる原因
過学習が発生するのには、主に3つの原因があります。
学習データが少ない・偏っている
機械学習モデルは、多様なデータを大量に学ぶことで「汎用的なパターン」を習得します。しかし学習データが少なかったり、特定の時期・属性・状況に偏っていたりすると、モデルはその限られたデータのパターンを過度に記憶してしまいます。
「社内に蓄積されているデータで機械学習をしたい」という場合、データ量や多様性が不十分なケースが少なくありません。
モデルが必要以上に複雑になっている
機械学習のモデルには「複雑さ」があります。単純なモデルは大まかなパターンを学びますが、複雑なモデルは細かい特徴まで学べる一方、ノイズ(偶然の揺らぎ)まで記憶してしまうリスクがあります。
ニューラルネットワークや深層学習(ディープラーニング)のモデルは特に複雑になりやすく、データ量が少ない場合に過学習のリスクが高まります。
検証プロセスが不十分
学習データで訓練したモデルを、同じ学習データで評価してしまうという落とし穴があります。これは「自己採点で100点」の状態であり、本番での性能をまったく保証しません。
適切な検証プロセス(後述するホールドアウト法・交差検証)が設けられていないと、過学習に気づかないまま本番に出てしまうリスクがあります。
過学習を見分ける方法
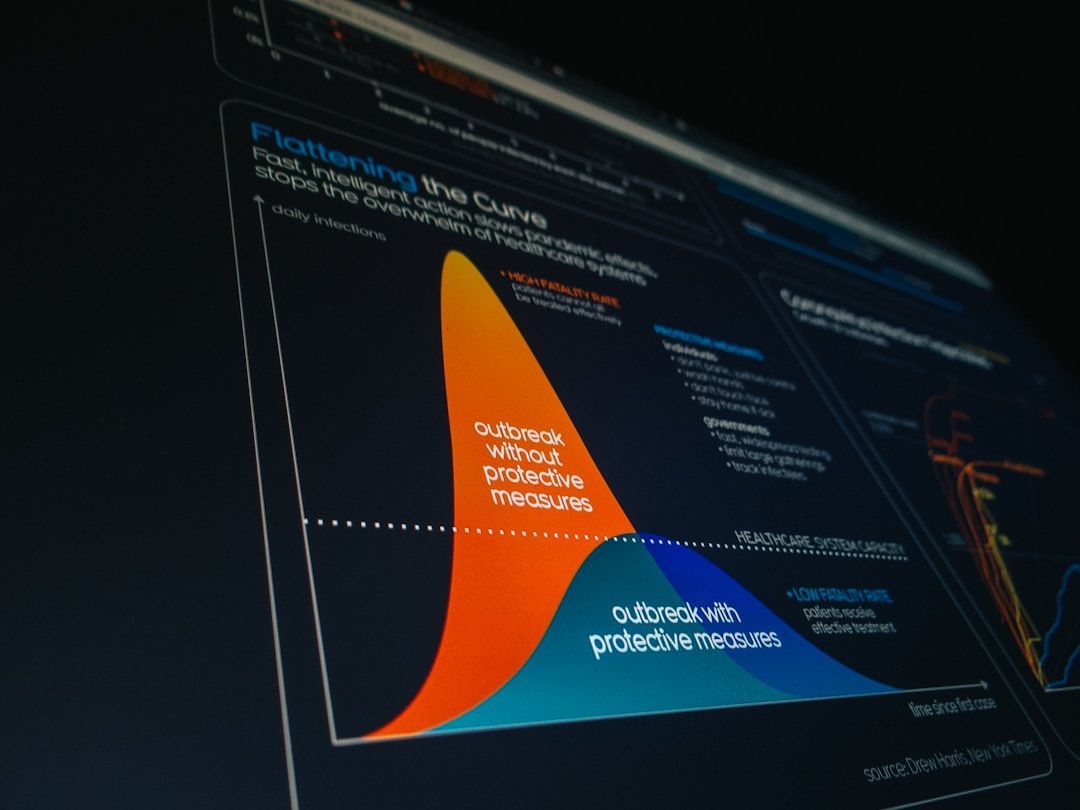
過学習が起きているかどうかは、適切な検証を行えば確認できます。
学習精度と検証精度の乖離を確認する
過学習の最も分かりやすいサインは、「学習データでの精度」と「テスト(検証)データでの精度」の乖離です。
健全なモデル: 学習精度 90% / 検証精度 88% (大きな差がない) 過学習のモデル: 学習精度 99% / 検証精度 65% (大きな乖離がある)
学習を重ねるにつれて学習精度は上がり続ける一方、検証精度が途中から下がり始める「学習曲線の乖離」は過学習の典型的なパターンです。
ホールドアウト法と交差検証法とは
過学習を検出するために広く使われる2つの手法があります。
ホールドアウト法: データをあらかじめ「学習用」と「検証用」に分割しておき(例: 8対2の比率)、学習に使っていないデータで最終的な精度を測る方法です。分かりやすく実施しやすい反面、分割の仕方によって結果が変わることがあります。
交差検証(クロスバリデーション)法: データをK個のグループに分割し、1グループずつ順番に検証用として使い、残りで学習する操作を繰り返す方法です。全データを検証に使えるため、より信頼性の高い評価ができます。ホールドアウト法より手間はかかりますが、精度評価の信頼性が高まります。
いずれの方法においても、「学習データと別のデータで検証している」ことが重要です。
過学習を防ぐ主な対策

過学習が確認された場合、または発生前に予防する場合、以下の対策が有効です。
データ面の対策(量と質を改善する)
- 学習データを増やす: より多くのデータを収集・活用することで、モデルが汎用的なパターンを学べるようにする
- データの多様性を確保する: 特定の時期・属性への偏りを解消し、本番環境で想定されるさまざまなパターンをカバーする
- データ拡張(Data Augmentation): 画像認識など一部の分野では、既存データを変形・加工して疑似的にデータ量を増やす手法も使われる
モデル面の対策(正則化・ドロップアウト)
-
正則化(L1・L2正則化): モデルが複雑になりすぎないよう、「モデルの複雑さにペナルティを与える」仕組みです。不要な特徴量の影響を抑えることで、汎用性を高めます。
-
ドロップアウト: 主にニューラルネットワークで使われる手法で、学習中にランダムで一部のノード(神経細胞に相当する処理単位)を無効化します。特定のパターンへの過剰な依存を防ぎ、モデルを「ロバスト(頑健)」にします。
-
モデルの簡素化(早期停止): 複雑すぎるモデルをあえてシンプルにしたり、学習を途中で止めたりすることで、過剰な記憶を防ぎます。
検証面の対策(継続的なモニタリング)
-
学習曲線のモニタリング: 学習の進捗とともに学習精度・検証精度を継続的に記録し、乖離が生じていないか確認する
-
本番データとの分布比較: 学習に使ったデータと、本番で実際に入力されるデータの傾向を比較し、大きなズレがないかを確認する
AI開発を発注する立場の担当者へ:品質確認のポイント
ここからは、AI開発を外注している担当者向けに、過学習リスクを確認するための実践的なアドバイスをお伝えします。
発注先に確認すべき3つの質問
開発会社との定例MTGや報告時に、以下の3点を確認してみてください。
質問1: 学習データ・検証データ・テストデータはどのように分割していますか?
適切な開発では、データを「学習用」「検証用」「テスト用」の3種類に分けて使います。「学習した同じデータで精度を測っている」という状況は過学習を見逃す典型的な落とし穴です。分割比率と分割方法(ランダム分割か、時系列を考慮した分割か)を確認しましょう。
質問2: 学習曲線は確認していますか?
「学習データでの精度」と「検証データでの精度」が並べて記録・表示されているかを確認してください。この2つの精度が大きく乖離している場合は過学習のサインです。「精度98%」という一つの数字だけでなく、「どのデータで測った精度か」を必ず確認する習慣をつけましょう。
質問3: 本番データと学習データの傾向に違いはないか確認していますか?
本番で実際に使うデータが、学習に使ったデータと同じ傾向を持っているかどうかが重要です。時期・属性・業務プロセスの変化などによって傾向が変わっていないかを確認しましょう。特に「本番稼働から時間が経過したモデル」は、この確認が必要になります。
過学習リスクが高いプロジェクトの特徴
以下に当てはまる場合は、過学習リスクを意識的にチェックすることをおすすめします。
- 学習データが少ない(数百〜数千件程度)
- 学習データが特定の時期・状況に偏っている(例: コロナ禍のデータのみ)
- 検証プロセスが明示的に設定されていない(「精度は高い」という報告だけで、どのデータで測った精度かが不明)
- 本番稼働から長期間経過している(環境・傾向の変化を考慮していない)
- PoC(実証実験)段階のモデルをそのまま本番に使っている
こうした状況に当てはまる場合は、開発会社に検証プロセスの見直しを依頼することを検討してみてください。
まとめ
本記事では、過学習(オーバーフィッティング)について以下のポイントを解説しました。
- 過学習とは: 機械学習モデルが学習データに過剰適合し、未知データへの精度が落ちる状態
- なぜ問題か: 開発段階では発覚せず、本番稼働後に精度低下として現れるため
- 原因: データの少なさ・偏り、モデルの複雑化、不十分な検証プロセス
- 見分け方: 学習精度と検証精度の乖離、ホールドアウト法・交差検証による確認
- 発注者として: 「どのデータで精度を測っているか」「検証プロセスがあるか」を確認する
AI・機械学習システムの精度問題は、過学習以外にも原因があります。AI導入をより効果的に進めるためのヒントについては、中小企業のAI導入率はなぜ低い?導入すべき5つの理由と成功への道筋や生成AIで業務改善を加速!中小企業が今すぐ始められる活用方法と成功事例を徹底解説もあわせてご覧ください。
はじめての AI 導入ガイド――中小企業が失敗しないための7ステップ
この資料でわかること
AI導入を検討しているが「何から始めればよいか分からない」中小企業の意思決定者に対し、導入プロジェクトの全体像を一気通貫で提示し、「自社でも着手できる」という確信と具体的な行動計画を持ってもらうこと。
こんな方におすすめです
- AI導入を検討しているが、何から始めればよいか分からない
- ベンダーの選び方や費用感がつかめず、判断できない
- 社内でAI導入の稟議を通すための資料が必要
入力いただいたメールアドレスにPDFをお送りします。
よくある質問
- 発注先から「精度98%」と報告されたら、過学習を疑うべきですか?
数字単体では判断できません。「どのデータで測った精度か」を確認するのが重要です。学習データとは別の検証データで測った精度かどうか、学習精度と検証精度が並べて報告されているかを確認し、両者が大きく乖離していなければ過信せず受け止めて問題ありません。
- 過学習が起きていた場合、追加費用なしで開発会社に修正してもらえますか?
契約内容によります。検収基準や精度目標を契約・仕様書で明示している場合は瑕疵対応として無償修正の対象になり得ますが、明示していなければ追加開発扱いになることが多いです。発注時に「本番相当データでの精度目標」を要件に含めておくことをおすすめします。
- 過学習かどうかを発注者自身が技術的に検証することはできますか?
自分でコードを検証する必要はありません。発注者は「学習・検証・テストデータをどう分割したか」「学習曲線で両精度の乖離はないか」「本番データと学習データの傾向は近いか」の3点を質問で確認すれば十分です。技術的な実装は開発会社に任せ、検証プロセスの有無を見極めることが役割です。
- 学習データが少ない場合、過学習を避けるには発注を見送るべきですか?
見送る必要はありませんが、進め方の調整は必要です。データ拡張やシンプルなモデルの採用、交差検証の徹底でリスクを抑えられます。まずPoC(実証実験)で本番相当データを使った精度を確認し、実用水準に届くか見極めてから本開発に進む段階的な進め方が安全です。
- 本番稼働後しばらく経ってから精度が落ちてきました。これも過学習ですか?
過学習というより「データドリフト」の可能性が高いです。市場環境や顧客傾向の変化で、本番データが学習時のデータと乖離して精度が低下する現象です。定期的に本番データの傾向を確認し、必要に応じてモデルを再学習する運用保守を開発会社と取り決めておくことが対策になります。


